『茶漉』はコーパスから用例およびコロケーション情報を抽出するシステムである。以下に特長を挙げる。
このシステムは、「日本語学習辞書編纂に向けた電子化コーパス利用によるコロケーション研究」(代表者:名古屋大学国際言語文化研究科日本言語文化専攻教授 大曽美恵子)というタイトルの科学研究費補助金によるプロジェクトの一環として開発されたものである。システム設計・開発には深田淳があたり、名古屋大学国際言語文化研究科日本言語文化専攻の大学院生、寺島啓子氏、寺島佳子氏、萩原由貴子氏の協力を得た。開発はLinux上でC言語(gcc)を用いて行われた。
『茶漉』という名称の由来は以下の通りである。当システムは、コーパスを検索可能なデータファイルに変換する段階で形態素解析システム『和布蕪』(奈良先端科学技術大学院大学自然言語処理学講座開発による)を用いる。和布蕪の前身は『茶筌』というシステムであったが、茶筌を用いて立てたお茶(データ)から必要な情報のみを漉し取って取り出すシステムということで『茶漉』とした。
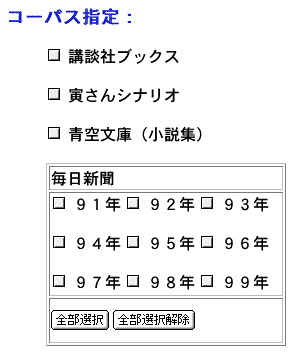
現在一般公開が可能なコーパスファイルは「青空文庫」から抜粋した小説のコーパスのみである。科研プロジェクトチームが使用可能なコーパスのリストは以下の通り。
コーパスについては、基本的にどんなテキストファイルでも『和布蕪』で処理をして、さらに数種類のプログラムで処理を施せば、『茶漉』で検索が可能になる。従って、日本語コーパスが増えれば増えるほど、『茶漉』の有用性は増すことになる。
検索の設定にあたってまずすべきことはコーパスの指定である。コーパスはチェックボックスをクリックすることで複数指定可能である。指定を解除するには再度クリックする。用例が多数見つかる可能性がある場合は、少数のコーパスでまず試してみるとよいだろう。用例数が多すぎると処理に時間がかかるし、ブラウザがメモリ不足になる可能性も出てくるからである。
ここではまずスパン(span)の設定をする。スパンとは検索キーワードの前後の語数で規定され、コロケーションを持つ語を探す範囲となる。スパンは小さければ小さいほど処理効率がよくなるので、不必要に長いスパンを設定しないことが肝要である。
![]()
前後を任意の整数に変更できるが、必ず半角文字を使うこと。
例1:「本腰」とコロケーションを持つ動詞(「入れる」など)を検索する場合は、前文脈を見る必要はないので「前0語」として、後文脈は助詞と動詞で二語だとすれば「後2語」と指定すればよい。
例2:終助詞的に用いられる「から」と呼応する副詞(「せっかく」「何しろ」など)を調べる場合は、後文脈はないので0語でよい。前文脈は文頭までを調べたいので15とか20とかを指定すればよい。(短い文の場合は、文の境界を越えて一つ前の文までスパンに入ってしまうこともある得るが、これは仕方がない。)
次に検索条件の設定にはいる。この表はほぼ同じものが七回繰り返されているが、四番目のkwが検索キーワードを表していて、-3~-1はkwの前の三語、+1~+3は後続する三語を表している。kwの欄以外は全く同じなので、-3の欄だけを取り出して解説する。

各欄には語形と品詞の指定ができるようになっている。語形は、「を」「政府」「需要」など完結した語を入力することもできるし、「駄*」「*語」などの前方一致、後方一致の指定でもよい。「駄*」は「駄」で始まる語(「駄菓子」「駄洒落」など)で、「*語」は「語」で終わる語(「英語」「フランス語」など)の意味である。アステリスク文字(*)は半角文字でなければならない。語形の指定にあたっては、『和布蕪』が文をどのように形態素に分けるかを知らなければならない。例えば「可能性」「経済性」など「性」で終わる語という意図で「*性」とやっても、『和布蕪』は「性」を別の形態素として分離するので、うまくいかない。『和布蕪』が文やフレーズをどのように解析するかを手軽に調べるために『ミニ和布蕪』を準備した。語形指定は一語に限らず、任意の語を羅列することができる。例えば、「桜,さくら,サクラ」のように。区切り文字は半角のコンマか"|"文字が使用可能である。
次に「含」「除外」のオプションの説明をする。-3のスロットの語形に「を」を指定して「含」とした場合は、検索キーワードの三つ前の語が「を」であることという条件を表す。「除外」を選択するとその逆で、検索キーワードの三つ前の語が「を」以外の語であることという条件になる。
「全活用形」チェックボックスは、語形に活用語(動詞、形容詞、助動詞)の辞書形を指定した場合に効力を発揮する。例えば、語形=「見る」と指定して「含」を選び「全活用形」をチェックした場合は、当該スロットに「見る、見て、見れ、見ろ...」などどの活用形が来てもよいという条件を指定したことになる。
品詞の指定もほぼ同様であるが、アステリスク文字(*)は使えない。「動詞」「名詞」「副詞」などの品詞名以外に「連用形」「未然形」などの情報も検索条件に含めることができる。どんな情報が入っているかは『ミニ和布蕪』で調べられたい。
検索キーワード(kw)の欄には、語形の「含」「除外」のオプションがない。またここではアステリスク文字(*)も使えないので注意されたい。
以上の説明だけでは実際にどう使ったらいいのかはっきりしないかもしれないので、「検索条件設定の例」のセクションも参考にされたい。
出力フィルターとは、コロケーション強度の計算に含める語を制限するものである。例えば、動詞とのコロケーションのみに興味があれば、品詞=「動詞」とすればその他の品詞をコロケーション計算から除外できるので、処理効率が向上するし、出力も読みやすくなる。
活用形をまとめて集計するというオプションは、「歌う」「歌わ」「歌い」などの同一語の活用形を同一と見なして、合算して集計するというオプションである。これがチェックされていないと、各活用形が別々に集計される。チェックした場合は、出力に辞書形のみが表示される。
tスコアおよびMIスコアはコロケーションの強度を表す指標であり、数値が大きければ大きいほどコロケーションが強いことを示す。tスコア敷居値、MIスコア敷居値とは、コロケーション出力に表示されるために最低限必要な値のことである。デフォルト値はt=2.0, MI=3.0で、これはコーパス言語学でよく使われる目安である。敷居値を低くすればより多くの語が表示されることになる。
kwicとはkeyword in contextの略で、キーワードとその文脈を表示する表示形式のことである。用例を調べたい時にはこの出力が見られるように「kwic出力」チェックボックスをチェックする。
kwic出力形式は二通りある。第一は、語数指定によるもので検索キーワードの前後何語ずつと指定できる。第二は文全体という指定で、検索語を含む文全体が表示される。いずれの場合も検索キーワードだけは赤で表示される。
「形態素区切り文字列」とは、kwic出力の中で形態素(語)と形態素を区切るために挿入する文字列のことである。デフォルトは半角のスペースが二つである。区切り文字が不要な場合は削除して空にしておけばよい。
このセクションでは、実際に『茶漉』で検索条件を設定したところを観察して、その検索を実行し、『茶漉』の使い方を体験してもらうように設計してある。各例において、検索条件を設定したページを開いたら、設定と赤文字で書かれた解説をよく吟味した上で、一番下にある「検索開始」ボタンをクリックすること。
(「お茶をいれる」の意味で)「お茶を作る」というような表現は日本語には出てこない。これはコロケーション情報が自然な(ネイティブらしい)日本語を習得するのに必要なことを示している。
この検索のための条件設定例は、ここをクリック。
検索が終わったら、kwic出力設定を変えたりすると結果がどう変わるかを見てみる。
各種辞典には「せっかく~だから」の呼応関係の記述しか見られないが、他にもコロケーションを持つものがあるのではないか。
この検索のための条件設定例は、ここをクリック。
これはコロケーションではなく用例検索の例である。「誘う」と聞くと「人が人を誘う」というような例が第一に思い浮かぶが、有生名詞でないものも出現するかどうか。
この検索のための条件設定例は、ここをクリック。